

统计学习方法
MCMC
Monte Carlo
就是“用随机抽样进行模拟数值计算”,均匀撒点求面积、用样本均值计算总体均值,都算Monte Carlo方法,毕竟,Monte Carlo是赌城的名字而非科学家的名字
注意:此处需要概率分布是已知的!你的目标就是求某一概率密度分布$p(x)$下的某个统计量,当然需要事先知道该概率分布$p(x)$ 一个潜在的问题是,你想用“样本”去近似算统计值(依靠大数定律),这要求手中有按照$p(x)$分布的样本,但你很可能没有
因此,Monte Carlo的核心是随机抽样
有多种方法进行随机抽样,比如:
直接抽样法:最直观的,依赖于均匀抽样与CDF的反函数(搜索一下就知道了),但该方法不一定可操作,比如,求CDF要积分$p(x)$,这个积分很可能不好算,因此有了下面的方法
接受-拒绝法: 在有某个已知分布$q(x)$的抽样的基础上,让这些抽样变成符合$p(x)$的抽样。如何变?比如我按照$q(x)$抽取到了点$x^\ast$,概率密度为$q(x^\ast)$,但目标是:生成的$x^\ast$得按照概率密度$p(x^\ast)$分布,因此,我以$\frac{p(x^\ast)}{cq(x^\ast)}$的概率采纳这个样本,将它加入最终的样本序列中,剩余的概率抛弃它,这就得到了按$p(x)$分布的抽样。但是,很可能$\frac{p(x^\ast)}{cq(x^\ast)}$很小很小,导致大部分时间都在抛弃,效率低下,因此才有了下面的方法
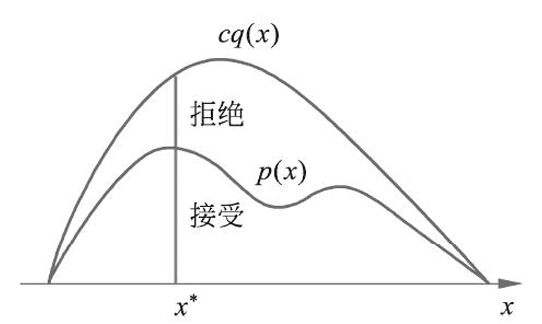
- Markov Chain:随机游走也是一种抽样!比如在三个点A,B,C之间按照某种概率游走,每一时刻的位置,构成一个序列,比如A,C,B,A,C,C……这就是对于A,B,C的一种抽样。下面就是讲这种方法
Markov Chain
Markov性
某一个物理量具有Markov性,即该物理量的未来只依赖于该物理量的现在,不依赖于其过去,称它某一个时刻的值为状态
例子:考察质量为$m$的质点在已知势场中的运动,$(\vec{x}(t),\vec{v}(t))$就具有Markov性,因为已知$t_0$时的$\vec{x}(t_0)$和$\vec{v}(t_0)$,今后的$\vec{x}(t)$和$\vec{v}(t)$全都可以求出来了
但是$\vec{x}(t)$是不具有Markov性的:已知$\vec{x}(t_0)$,还无法得知$\vec{x}(t_0+\Delta t)$。因为还需要知道$t_0$时的速度信息,而$t_0$时刻的速度信息是已知$\vec{x}(t_0)$和$\vec{x}(t_0-\Delta t)$才能算出来的,因此,这需要用到$\vec{x}(t_0-\Delta t)$这一过去的信息,未来还和过去相关了
总结来说,如果演化方程中,含有导数项,就与历史有关,就不具有Markov性,如下
满足Markov性的状态演化方程:
$$
\begin{align*}
\vec{x}(t_0+\Delta t)&=\vec{x}(t_0)+\vec{v}(t_0)\Delta t
\newline\newline
\vec{v}(t_0+\Delta t)&=\vec{v}(t_0)+\frac{-\nabla V(\vec{x}(t_0))}{m}\Delta t
\end{align*}
$$
不满足的:
$$
\vec{x}(t_0+\Delta t)=\vec{x}(t_0)+\dot{\vec{x}}(t_0)\Delta t
$$
因此,初中物理就有一句话:“物体的运动状态就是指位置和速度”。现代控制理论中的状态概念之所以有用,就是因为Markov性
许多定义与定理
约定用$i,j$字母代表状态,$X_t$代表第$t$步时所处状态的随机变量,其取值就是$i,j,\dots$这样的状态
定义 一个随机变量序列$\set{X_0,X_1,\dots, X_t,\dots}$,若:
$$
P(X_t|X_0,\dots ,X_{t-1})=P(X_t|X_{t-1})
$$
就是具有Markov性的随机序列,称为Markov链
定义 状态分布:指Markov链在某一时刻的概率分布:
$$
\pi(t)=\begin{pmatrix}
\pi_1(t)\\
\pi_2(t)\\
\vdots \\
\end{pmatrix}
$$
其中,$\pi_i(t)$代表$t$时刻恰在状态$i$的概率,即$\pi_i(t)=P(X_t=i)$
下文中,请注意区分“状态”与“状态分布”
定义 状态转移概率矩阵,其分量$p_{ij}=P(X_t=i|X_{t-1}=j)$,即从$j$移动到$i$的概率,因此,$\pi(t)=P\pi(t-1)$
定义 设给定的Markov链,其状态转移概率矩阵为$P$,如果存在状态空间中的一个分布$\pi=(\pi_1,\pi_2,\dots)^\top$满足$\pi=P\pi$,则$\pi$称为平稳分布
定义 给定Markov链,若对于任意的两个状态$i$与$j$,均存在一个$t$满足
$$
P(X_t=i|X_0=j)>0
$$
则称该Markov链不可约
其实,如果存在$t$使得$P(X_t=i|X_0=j)>0$,则记$j\to i$,若还有$i\to j$,则称$i$与$j$互通,记为$i\leftrightarrow j$。这个互通其实是一个等价关系,因此可以依此划分状态,把互通的状态记为一类。不可约说的就是:该Markov链仅仅只有一类
定义 某一个状态$i$,从它自己出发回到自己概率非零,那么集合$\set{t:P(X_t=i|X_0=i)>0}$就非空,这个集合中所有数的最大公约数就是$i$状态的周期,若最大公约数为1,则该状态是非周期的,所有状态都是非周期的Markov链,称为非周期的Markov链
定义 首达概率:$p^t_{ij}$指$0$时刻从$j$出发,$t$时刻首次到达$i$的概率。又记$f_{ij}=\sum\limits_{t=1}^\infty p^t_{ij}$,这里的$f_{ij}$指的是能经过有限步,从$j$到$i$的概率
定义 常返状态:如果$f_{ii}=1$,那么状态$i$就是常返(recurrent)状态
定义 正常返状态:记$\mu_i=\sum\limits_{t=1}^\infty t p^t_{ii}$,这代表的就是$i$出发回到$i$的步数的期望值,如果$\mu_i<\infty$,则称$i$为正常返状态,若$\mu_i=+\infty$,称为零常返状态
定义 可逆:如果有状态分布$\pi=(\pi_1,\pi_2,\dots)^\top$,使得对于任何状态$i,j$,对任意的$t$满足细致平衡方程:$p_{ij}\pi_j=p_{ji}\pi_i$,则称Markov链可逆
定理 满足细致平衡方程的状态分布$\pi$就是平稳分布,$P\pi=\pi$
证明:$(P\pi) _ i=\sum _ j P _ {ij}\pi _ j=\sum _ j P _ {ji}\pi _ i=\pi _ i\sum _ j P _ {ji}=\pi _ i$
定义 称Markov链为遍历链,指的是它不可约,正常返,非周期
定理(遍历) 若为遍历Markov链,那么对于任意的状态$i,j$,有:$\lim\limits_{t\to\infty} p^t_{ij}=\frac{1}{\mu_j}$,且这就是平稳分布!
证明 参见https://www.math.pku.edu.cn/teachers/lidf/course/stochproc/stochprocnotes/html/_book/StocProc.pdf 定理5.8 定义5.13 定理5.12 待填
这个定理之所以好,是因为我们在Markov链上游走,最后会落到某个极限的分布中去,这个极限分布如果恰好等于平稳分布,而且还是我们想要的那个样本分布,那么“游走”就可以当成“采样”了!否则,即使苦心经营了一个平稳分布,但是怎么游走也走不到那里去,我们的计划仍然会泡汤
Metropolis Hastings算法
注:下面说的转移核$p(x,y)$,其实指的是$x$转变到$y$的概率密度函数,对应着离散的情形中的矩阵元素$p_{ij}$(从$j$到$i$的转移概率)。譬如,显然有:$\int p(x,y)dy=1$,因为$x$转变到各个新状态的概率和为一
思想:该算法就靠的是一个转移核为$p(x,x’)$的Markov链。按这个转移核进行随机游走,时间够长后,能够得到一个平稳分布$p(x)$,就是目标的样本分布!这样,样本就随着游走的进行,源源不断生成了
在该算法中,如何得到$p(x,x’)$的核心公式:
$$
p(x,x’)=q(x,x’)\alpha(x,x’)
$$
其中:
$q(x,x’)$叫建议分布,它是另一个不可约的Markov链的转移核,回顾一下不可约的定义,就知道$q(x,x’)>0$恒成立,这保证了分母不为零
$\alpha(x,x’)$叫接受分布,定义为$\alpha(x,x’)=\min\set{1,\frac{p(x’)q(x’,x)}{p(x)q(x,x’)}}$
按照$p(x,x’)$游走的含义是什么呢?当我决定下一步去哪的时候,先去“建议分布”那里寻求建议,它会按照$q(x,x’)$给你候选状态$x’$,然后,“接受分布”告诉你要不要接受它:以$\alpha(x,x’)$的概率接受候选,转移到那里去;以$1-\alpha(x,x’)$的概率不接受,“采样失败”,干等着,下一轮再来。继续重复执行这一方法,夜以继日地游走,就能够得到源源不断的抽样,这就是Metropolis Hastings算法
回答一下为什么这个算法得到的抽样是平稳的:
定理 由该转移核得到的Markov链是可逆的,即:$p(x)p(x,x’)=p(x’)p(x’,x)$,且$p(x)$就是平稳分布
证明:
$$
\begin{align*}
p(x)p(x,x’)&=p(x)\min\set{q(x,x’),\frac{p(x’)q(x’,x)}{p(x)}}
\newline
&=\min\set{p(x)q(x,x’),p(x’)q(x’,x)}
\newline
&=p(x’)q(x’,x)\min\set{\frac{p(x)q(x,x’)}{p(x’)q(x’,x)},1}
\newline
&=p(x’)p(x’,x)
\end{align*}
$$
当然,满足细致平衡方程自然是平稳分布(鉴于这里是连续的,之前的求和得换成积分,再写一下):
$$
\int p(x)p(x,x’)dx=p(x’)\int p(x’,x)dx=p(x’) \quad \square
$$
Metropolis思路梳理
再理一下思路:
目标是要得到依$p(x)$分布的随机样本,方法是构造一个Markov链
构造Markov链的用处在于,在上面游走很久后,平稳分布就是$p(x)$!
想构造Markov链,要先知道怎么游走,“怎么游走”在数学上就是转移核。那请问转移核$p(x,x’)$又是怎么来的?答:给出建议分布和接受分布后得到
不过,接受分布是关于$q(x,x’)$和$p(x)$的函数,所以,只要给出建议分布$q(x,x’)$,就足以得到$p(x,x’)$了
“形上谓道”的内容说完了,下面来看“形下谓器”的东西:$q(x,x’)$该选什么
第一种选法是对称选取$q(x,x’)=q(x’,x)$,这样$\alpha(x,x’)$很简单,就是$\min\set{1,\frac{p(x’)}{p(x)}}$,具体的,可以选$q(x,x’)\propto \exp(-\frac{(x-x’)^2}{2})$等等
第二种选法叫独立抽样,更加简单,它认为下一刻到哪,和此刻所在位置都没关系!就是$q(x,x’)=q(x’)$,这样,$\alpha(x,x’)$也很简单,就是$\min\set{1,\frac{p(x’)/q(x’)}{p(x)/q(x)}}$
总结:
明确目标$p(x)$
选择建议分布$q(x,x’)$(自己选)
构建$p(x,x’)$,这就是想要的Markov链
开始按照$p(x,x’)$的转移规则游走
游走足够长时间后,认为进入平稳分布阶段了,把这之后游走的结果取出来,作为$p(x)$的采样
达到平稳分布前的时期称为燃烧期,该期间的样本是舍弃掉的,因为还没到平稳的$p(x)$分布呢
Gibbs采样
为什么要Gibbs?答:Metropolis算法仍然有“拒绝”样本的可能,“拒绝”就是白费了一次的意思,存在效率低下的隐患,而Gibbs采样方法就没有这个问题,不会停留在某个状态
首先声明,Gibbs抽样适用于多元随机变量联合分布
先看二元的例子,比如我的目标是密度函数$p$,那抽到点$x=(x_1,x_2)$的概率密度是
$$
p(x)=p((x_1,x_2))=p(x_1)p(x_2|x_1)
$$
(小心别和前面转移核的记号混起来,所以我多加了一层括号)同理,抽到点$x’=(x_1,x_2’)$的概率就是:
$$
p(x’)=p((x_1,x_2’))=p(x_1)p(x_2’|x_1)
$$
因此就有:
$$
p(x)p(x_2’|x_1)=p(x’)p(x_2|x_1)
$$
这个形式,对比一下细致平衡方程,发现有惊喜:令转移核为$p(x,x’)=p(x_2’|x_1)$以及$p(x’,x)=p(x_2|x_1)$,那上式不就是细致平衡方程嘛!那最后平稳分布啥的好性质不就都有了嘛!所以,我的游走规则(转移核)就这么愉快决定了
这,就是Gibbs采样。不用找建议分布,更没有什么拒绝的环节,简单明了
当然,因为必须要有别的分量(上例中的$x_1$)都相同,才能列出这个式子,所以每次只能变动一个分量。因此,想要Gibbs抽样一次,其实需要依次对每个分量都进行一次“固定别的分量”后的随机游走,等分量全部更新完,才得到新的样本点
在理解了二元情形后,把它写成多元通用的形式:
Gibbs抽样从一个初始点$x^{(0)}=(x^{(0)}_1,x^{(0)}_2,\dots,x^{(0)}_k)$出发,约定第$i$次得到的样本点记为:$x^{(i)}=(x^{(i)}_1,x^{(i)}_2,\dots,x^{(i)}_k)$
在第$i+1$步时:
先对第一个变量按照$p(x_1|x^{(i)}_2,\dots,x^{(i)}_k)$进行随机抽样,得到$x^{(i+1)}_1$
然后对第二个分量按照$p(x_2|x^{(i+1)}_1,x^{(i)}_3,\dots,x^{(i)}_k)$进行随机抽样,得到$x^{(i+1)}_2$
一直类推,对第$j$个分量按照$p(x _ j|x^{(i+1)} _ 1,x^{(i+1)} _ {j-1},x^{(i)} _ {j+1},\dots,x^{(i)} _ k)$进行随机抽样,得到$x^{(i+1)} _ j$,直到更新完所有分量
恭喜,已经得到了一枚新样本
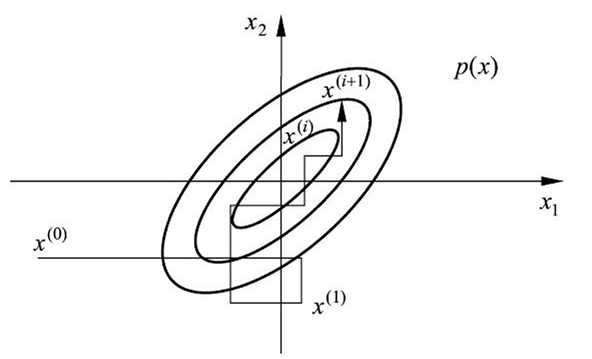
Gibbs采样与Metropolis的联系
其实,Gibbs是Metropolis的特例,下面就来证明之
Metropolis中取建议分布
$$
q(x,x’)=p(x_j|x_{-j})
$$
这里的$x_{-j}$代表此时除了$x_j$以外的其他的分量
相应的Metropolis接受分布就是:
$$
\alpha(x,x’)=\min\set{1,\frac{p(x’)p(x_j|x_{-j}’)}{p(x)p(x_j’|x_{-j})}}
$$
根据条件概率定义$p(x’)=p(x_{-j}’)p(x_j’|x_{-j}’)$以及$p(x)=p(x_{-j})p(x_j|x_{-j})$,上式就变为:
$$
\alpha(x,x’)=\min\set{1,\frac{p(x_{-j}’)p(x_j’|x_{-j}’)p(x_j|x_{-j}’)}{p(x_{-j})p(x_j|x_{-j})p(x_j’|x_{-j})}}
$$
由于$-j$那一部分的变量根本没变,$x_{-j}’=x_{-j}$,所以:
$$
\alpha(x,x’)=\min\set{1,1}=1
$$
果然,没有拒绝环节